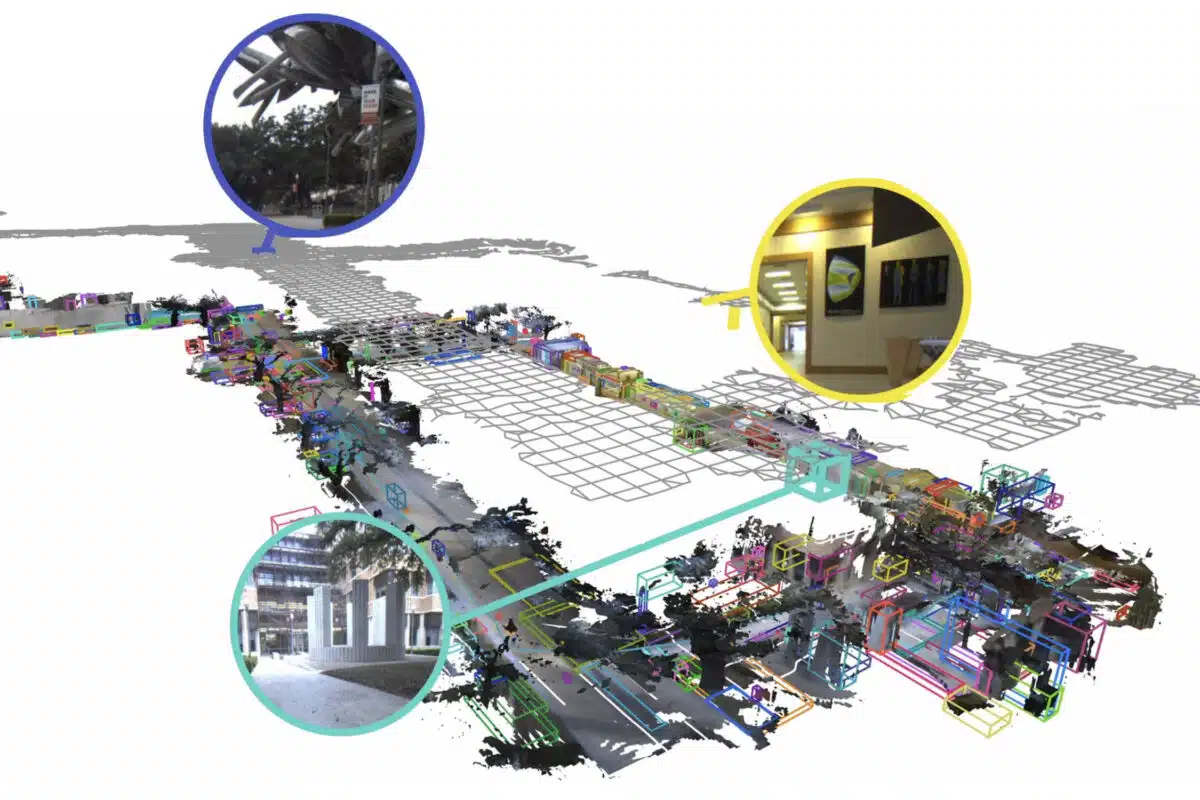
Using DAAAM, a robot can quickly access their memory to answer complex queries about its environment in plain language. Here, to answer a query, the robot searches its memory using the word "sculpture" to recall artworks it saw on campus. (Credit: MIT)
MIT Built an AI Memory System That Helps Robots Track What They Saw, Where, and When
In A Nutshell
- MIT researchers built an AI system called DAAAM that gives robots a form of long-term memory, tracking not just what they see but where and when they saw it.
- Unlike most systems that store snapshots frame by frame, DAAAM builds a running, timestamped map of everything the robot observes, which it can search using plain-language questions.
- A smart batching technique lets a large, slow AI description model keep up with real-time video, achieving roughly ten times the speed of the standard approach.
- Tested against competing methods, DAAAM answered object-related questions more accurately and completed navigation tasks correctly about 28% more often, though the system still struggles with unusual objects and faster platforms like drones.
Most people have walked into a room trying to remember where they left something days earlier. Humans do this naturally by combining memory of location, time, and appearance. Robots have historically been terrible at it. A team at MIT is trying to change that, and their early results suggest they are onto something.
Their system, called DAAAM (Describe Anything, Anywhere, at Any Moment), gives robots something close to long-term memory, tracking not just what a robot sees but where and when it saw it. It could one day reshape how robots operate in environments like factory floors, hospitals, or warehouses. For now it remains an early research system, but the performance gains over existing approaches are hard to ignore.
Most robotic systems can recognize objects or navigate spaces, but few can do both in real time while tracking how things change over minutes or hours. DAAAM is designed to do exactly that, building a running map of the world that includes detailed descriptions of many of the objects and places the robot observes, updated continuously as it moves. As robots take on more complex roles in daily life, the ability to answer questions like “where did you last see the red tool?” or “how long has that door been open?” becomes genuinely important.
How DAAAM Builds a Robot’s Memory in Real Time
DAAAM starts with a video feed from a depth-sensing camera, the kind that captures both color images and distance information, and turns that stream into what the researchers call a “4D scene graph,” a constantly updated database where every observed object and place gets its own entry: a written description, a location in 3D space, and a timestamp.
As the robot moves, the system draws outlines around every visible object in each frame and tracks them continuously, running at the camera’s full 10-frame-per-second rate. Generating written descriptions for those objects is the harder part. That requires a large, computationally expensive AI model, far too slow to run on every frame. To solve this, the system picks the clearest available frames for each object and batches them together for a single pass through the description model, running on a separate processing thread. Bundling many objects at once rather than processing them individually produced a roughly tenfold speed increase over the standard approach, which is what makes real-time operation possible at all.

A Robot Memory You Can Actually Question
Once the system has built its running map, a separate AI reasoning agent can search it using plain language. The paper illustrates this with a user asking about a sculpture near a campus building. The system searches its memory, reasons through what it found, and reports back with a description and the time it was last observed.
Because every tracked object retains timestamps alongside its location and description, the system can answer questions involving time: not just where something is, but when it was seen or how recently it changed. Earlier systems tended to store information frame by frame without linking observations across time, which made time-based questions nearly impossible to answer reliably.
Tested against competing approaches, DAAAM’s advantage was measurable. On a large-scale question-answering benchmark covering indoor and outdoor environments, it answered questions about objects more accurately, pinpointed locations more precisely, and tracked timing more reliably than the strongest alternatives. On a separate navigation test, where a robot had to identify and reach a sequence of locations described in plain language, DAAAM completed tasks correctly about 28% more often than the next-best method.
Where the System Falls Short
Researchers are candid about current limitations. An AI model called the Describe Anything Model generates the object descriptions, but it was trained on a relatively modest dataset and sometimes fails on unusual objects. In one example from the paper, the system confidently predicted that elevator doors had handles, a sign that the AI can fill in details from assumptions rather than from what it actually observed.
Speed limits also apply. While the system labels objects fast enough to keep up with a mobile ground robot, it may be too slow for aerial drones or virtual reality headsets. Because the system stores a running history of descriptions for every tracked object, that record could grow unwieldy over very long operation periods. The team flags summarization strategies as an area for future work, and the underlying model also lost some accuracy when tested on digitally simulated environments, since it was trained only on real-world imagery.
Robot Memory and the Real World
A searchable record of what a robot observed, where, and when opens up possibilities that current systems cannot support. A hospital assistant robot that could recall where equipment was left two hours ago, or a warehouse robot tracking component movement across a shift, would be a genuinely different kind of tool. As AI becomes more embedded in physical spaces, from smart homes to hospitals, maintaining an accurate log of surroundings starts to look less like a research milestone and more like a basic requirement. The MIT team has said the code and data will be released open-source.
Robots have long been able to see the world around them. DAAAM is a serious early attempt to let them remember it.
Disclaimer: This article is based on research presented at the Conference on Computer Vision and Pattern Recognition (CVPR). As with all scientific research, findings may be subject to replication and further study.
Paper Notes
Limitations
DAAAM’s authors identify several limitations. An AI model called the Describe Anything Model (DAM) generates the object descriptions, but it was trained on approximately 1.5 million samples, which the authors describe as relatively modest by current standards. As a result, the model sometimes fails on unusual or out-of-distribution objects and can produce incorrect descriptions that lean toward common assumptions, with the paper giving the example of predicting elevator doors as having handles. Annotation speed, approximately five new object fragments described per second on a single desktop graphics card, is sufficient for a mobile ground robot but may not keep pace with aerial drones or virtual reality applications. The system retains a full history of object descriptions over time, and the authors note this could pose memory scaling challenges over very long operation periods, flagging summarization strategies as an area for future work. Because DAM was trained exclusively on real-world imagery, it experiences some accuracy loss when applied to semi-synthetic benchmark datasets.
Funding and Disclosures
According to the paper, this work was supported by the ARL DCIST program and the ONR RAPID program. The authors stated that code and data would be released open-source upon acceptance; editors should confirm the repository is live before publication. Co-author Luca Carlone is currently on sabbatical as an Amazon Scholar; the press release notes that this research was performed at MIT and is not associated with Amazon.
Publication Details
Authors: Nicolas Gorlo (MIT graduate student), Lukas Schmid (professor, University of Technology Nuremberg), and Luca Carlone (associate professor, MIT Department of Aeronautics and Astronautics; principal investigator, Laboratory for Information and Decision Systems; director, MIT SPARK Laboratory). Contact: {ngorlo, lschmid, lcarlone}@mit.edu | Paper Title: Describe Anything Anywhere At Any Moment | Presented at: Conference on Computer Vision and Pattern Recognition (CVPR) | Preprint: arXiv:2512.00565v1.







